In this post, we will see why we needed HTTP/2, and more precisely, where HTTP/1.1 falls short. Then we will look at how HTTP/2 solves those problems at a high level.
The Shortcomings of HTTP/1.1
HTTP/1.1 was designed in 1997 for a web of simple, static pages. Who knew in what directions the Internet would evolve? The protocol worked well for the early Internet, but the Internet grew rapidly, and the requirements on both web servers and the protocol grew with it. Several problems arose:
Head-of-Line Blocking: The Traffic Jam Problem
HTTP/1.1 processes and sends requests sequentially on each connection. If one request stalls, everything behind it waits - like a traffic jam caused by a single slow car.
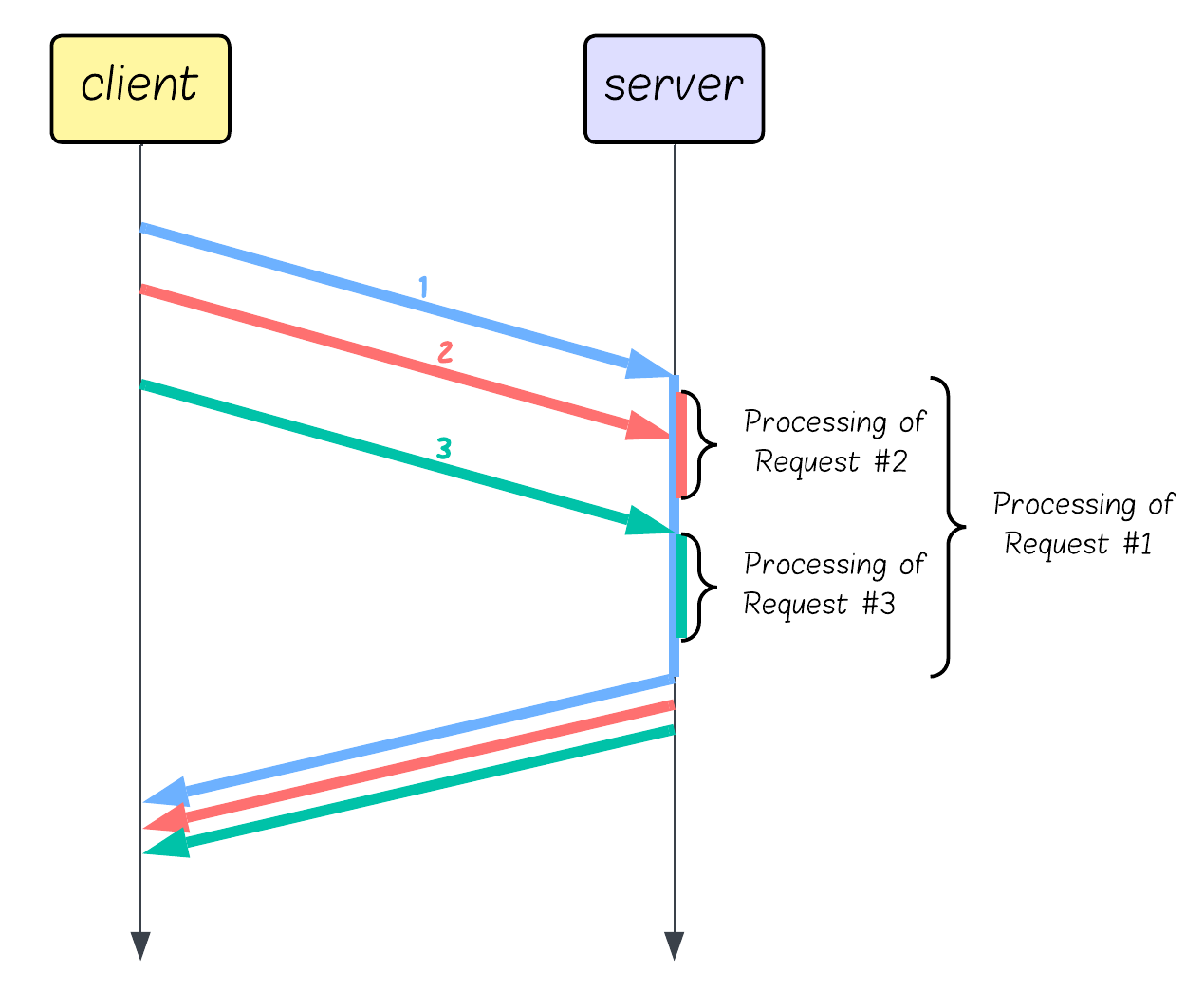
Real-world impact: A single slow database query or large image download can block critical CSS and JavaScript, causing your entire page to appear broken until that one slow resource finishes.
The situation was so bad that browsers began opening six concurrent connections per domain by default, just to fetch resources concurrently. But once all six are busy, new requests queue up and wait, even if the server could handle hundreds more. Every TCP/TLS connection also adds unnecessary overhead.
How bad was it? Even developers started using hacky workarounds to improve performance, like:
- Domain sharding:
assets1.example.com, assets2.example.com to get more connections
- Resource bundling: Combining 50 small CSS files into one giant file
- Inlining: Embedding images as base64 to avoid requests entirely
Every HTTP/1.1 request sends the same verbose headers over and over. No compression, no intelligence, just raw repetition.
“Do you remember what my User-Agent is from the request I sent 300 ms ago? Oh… you do? I don’t care, take it again.” - HTTP/1.1 client, probably.
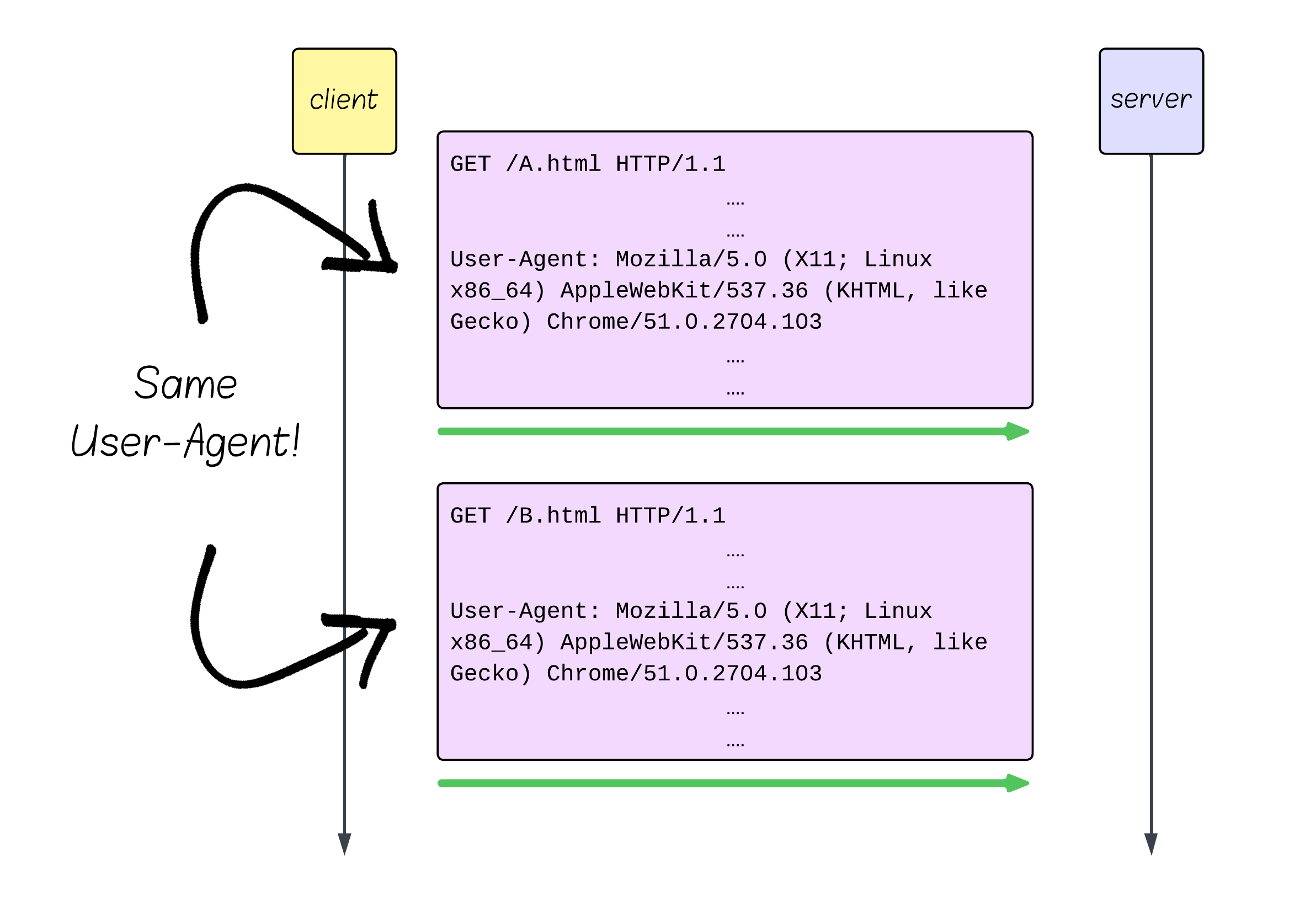
Textual Protocol: Human-Readable = Computer-Slow
HTTP/1.1 sends everything as human-readable text. While great for debugging with curl, it’s terrible for performance.
Computers have to parse this character by character, handle case variations, deal with optional whitespace, and validate syntax. It’s like forcing a calculator to read handwritten math instead of binary.
For example, how does the server know the headers part of the HTTP message has ended? It needs to find a blank line (\r\n) in the data, and only then does the payload begin. In order to know where the next HTTP message begins, the server needs to parse all of the headers, find where they end, and add the value of the Content-Length header (which also needs to be parsed). That is neither concurrency‑friendly nor efficient…
When you’re serving millions of requests per second, every microsecond of parsing overhead matters. Textual parsing is just… slow.
HTTP/2 to the Rescue
The Place of HTTP/2 in the World
Before we dive into solutions, let’s understand HTTP/2’s constraints.
HTTP/2 had to drop into a world with millions of servers, billions of clients, and countless proxies, load balancers, and CDNs, all expecting and built for HTTP/1.1.
The protocol designers faced a massive challenge: They couldn’t break the Internet.
Or more accurately, if they proposed breaking the Internet, no one would use HTTP/2…
So the design philosophy was:
-
Identical semantics. Every HTTP/1.1 concept (methods, headers, status codes) works exactly the same way. Your application code doesn’t change at all. Your GET /api/users request works identically (but travels differently).
-
Easy to Upgrade. Instead of an HTTP/1.1 module, put an HTTP/2 module, and everything will work. Servers could keep their old APIs.
-
Dual-stack servers - Servers can support both protocols simultaneously on the same port, transparently choosing which one to use based on client capabilities.
-
Faster than HTTP/1.1. “Fast is smooth, and smooth is fast,” the Navy SEALs say, I believe.
Why this matters: HTTP/2 couldn’t be “HTTP/2.0: now with breaking changes!” It had to be “HTTP/1.1, but actually fast.” The shared semantics guarantee that your existing code, APIs, and infrastructure continue working while getting dramatic performance improvements underneath.
In other words, HTTP/2 changes how HTTP/1.1 messages travel over the wire, but what they mean stays identical.
Now to the interesting part - how HTTP/2 solves each problem that HTTP/1.1 had:
Streams & Multiplexing
Multiple request-response flows simultaneously over one connection - no more blocking.
How is it implemented?
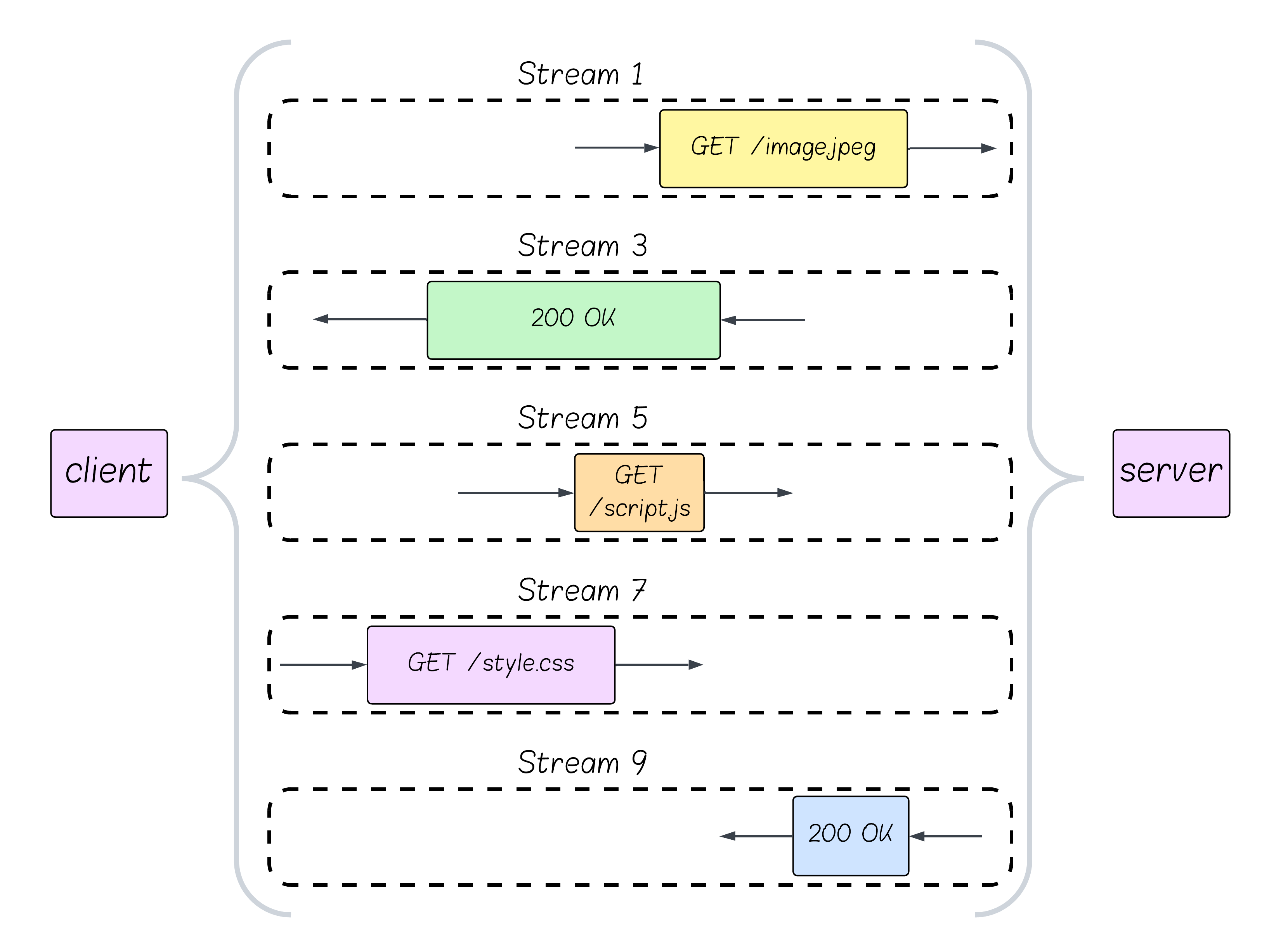
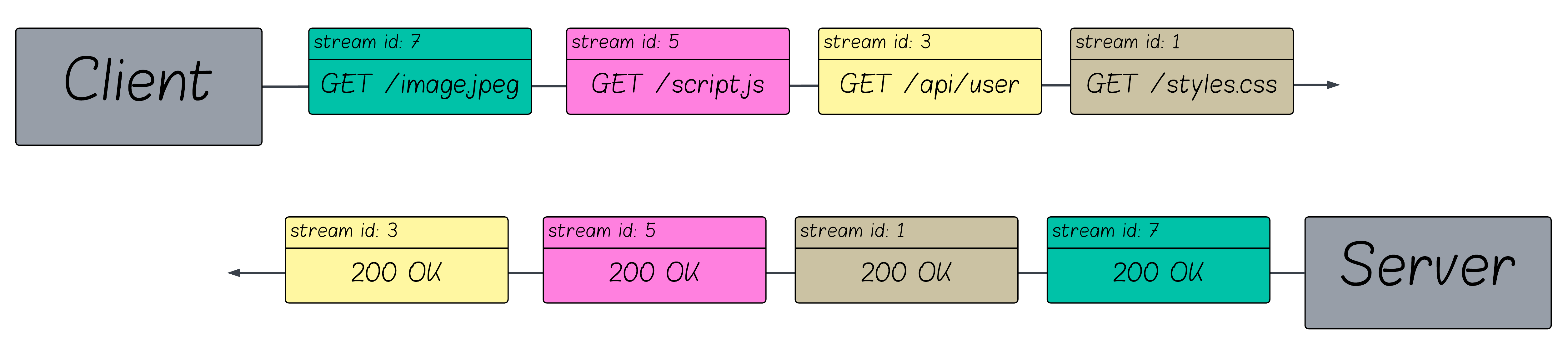
HTTP/2 introduces the notion of streams - which are virtual channels the client can open and on which to send a request and receive a response. Each stream can host only one request-response cycle.
Streams don’t have any other role, so it is like putting a tag on every request. When a response is received by the client, it will know which of its requests was the originating one.
Since streams are basically “tags”, multiple streams share the same TCP connection. So instead of HTTP/1.1’s “one request blocks everything,” you get “100 concurrent requests flowing simultaneously.”
How does this impact request fetching? Requests are sent when they are ready.
That slow database query that used to block your CSS? Now it’s just Stream 1 being slow while Streams 3, 5, 7, and 9 deliver your CSS, JavaScript, and images at full speed.
Binary Protocol
Computer-friendly format replaces human-readable text for efficiency.
The concept is simple: Instead of sending GET /api/users HTTP/1.1\r\n, HTTP/2 sends structured binary data that computers can parse in microseconds.
Think of it like the difference between:
- HTTP/1.1: Handing someone a handwritten note they have to read carefully
- HTTP/2: Handing someone a pre-filled form with checkboxes they can process instantly
Why this matters: When you’re processing millions of requests per second, the difference between “parse this text character by character” and “read these predefined binary fields” is massive. Servers can spend more time doing actual work instead of figuring out what you’re asking for.
Plus, no more ambiguity about case sensitivity, whitespace, or malformed requests. Binary is binary.
HPACK introduces two improvements:
- Huffman encoding
- The ability to reference previously used headers
Huffman Encoding
Huffman encoding is a classic compression technique: frequently used characters get shorter codes, rare characters get longer codes.
For HTTP headers, this means common letters like ‘e’, ‘a’, ‘t’ might be encoded in 4 bits, while rare characters like ‘z’ take 8+ bits.
The result: A typical header like Content-Type: application/json compresses from 30 bytes to about 20 bytes. Not revolutionary, but every byte saved over millions of requests adds up.
Think of it like text messaging shortcuts: ‘u’ instead of ‘you’, ‘r’ instead of ‘are’, but done automatically and optimally for HTTP header patterns.
Remember that HTTP/1.1 client quote? “Do you remember what my User-Agent is from 300 ms ago? I don’t care if you do, take it again”
HPACK’s response: “Actually, I do care. It’s index #62. No need to send it over again…“
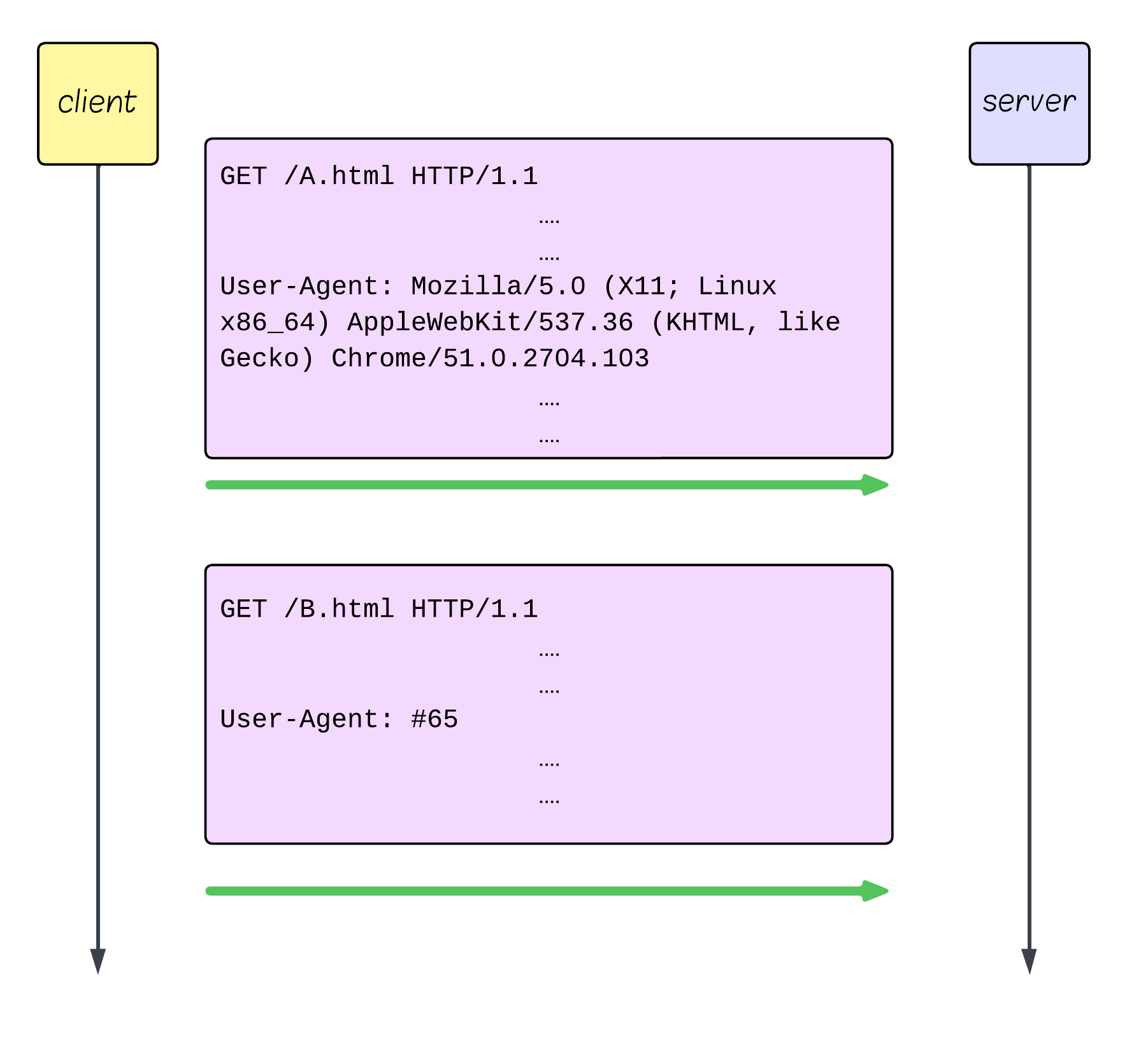
HPACK maintains a static table - of common headers like :method: GET = index 2. Those headers can always be referenced.
It also maintains a shared dynamic table between the client and server, into which recently used headers get inserted automatically.
It’s like having a conversation where instead of repeating “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36…” every time, you just say “#62”.
A Quick Note on HTTP/2’s “Failed” Features
I think it’s worth mentioning that HTTP/2 wasn’t perfect either. Two of its “hard selling” features ended up being… bad.
Most of the explanations of HTTP/2 discuss them in (too much) detail - I think it’s pointless. Both of them are not used anymore, but it’s worth knowing (a little bit) about them:
Server Push - The idea of servers proactively sending resources sounded amazing. In practice? It often wasted bandwidth by pushing resources the client already had cached. Most browsers removed support for it.
Stream Prioritization - HTTP/2 introduced a system where clients could tell servers “send me CSS before images, and critical JavaScript before analytics.” Sounds perfect, right?
Well…
The prioritization system was so complex that most servers implemented it wrong. The web got faster despite prioritization, not because of it. It was quickly deprecated.
There was also a design flaw in the Streams Concurrency Limits mechanism. To prevent DoS attacks, the protocol introduced a mechanism to limit how many streams a client can open. It was found to be flawed and was exploited by the Rapid Reset vulnerability, and later by the MadeYouReset vulnerability.
The stream concurrency limits system was replaced by a superior one in HTTP/3.
Even protocol designers can’t predict the future perfectly. But HTTP/2’s core innovations (multiplexing, binary framing, header compression) remain game changers.
What’s Next?
Want to go deeper into HTTP/2? Start with Part 1: frames, streams, and protocol flow.